
بررسی اختصاصی کارت گرافیک گیگابایت AORUS GeForce RTX 2080 Ti XTREME

با بررسیِ اختصاصی راندمانِ یکی از قویترین مدلهای جیفورس RTX 2080 Ti از شرکت گیگابایت با زومجی همراه باشید.
حدودِ ۷ ماه پیش و در اوایل شهریورماهِ ۱۳۹۷ بود که کارتهای گرافیک RTX 2080 و RTX 2080 Ti انویدیا رسما معرفی شدند و به این ترتیب شرکتِ انویدیا یکی از پیشرفتهترین محصولاتِ خود در صنعت تراشههای گرافیکیِ پیسی را به دنیا معرفی کرد. معماریِ تورینگ با قابلیتهای تا به حال دیده نشده در محصولاتِ تجاری عرضه شد و به ادعای انویدیا انقلابی در تاریخِ توسعهی تراشههای گرافیکی ایجاد کرد که تاثیرِ آن در بازیهای جدید به مرور مشهودتر خواهد شد.
مقالهی مرتبط
زومجی طبق روال همیشگی و همان گونه که کارتِ پرچمدارِ نسل قبلی یعنی GTX 1080 را به فاصلهی کوتاهی پس از معرفی و عرضه بررسی کرده بود، این بار هم قصد داشت در اولین فرصت یکی از محصولاتِ عرضه شده بر مبنای معماریِ جدید را دریافت و بررسی کند، اما سالِ گذشته به علتِ شرایطِ پیش آمده در کشور، با مشکلاتِ پیشبینی نشدهای مواجه شدیم که دریافت نمونهی محصولاتِ نمایندگیها را با تاخیری چند ماهه مواجه کرد و اشتیاقِ ما برای بررسیِ زود هنگامِ این محصول بی پاسخ ماند.
به هر روی در این مقاله قصد داریم AORUS GeForce RTX 2080 Ti XTREME ساختهی جدید شرکت گیگابایت را بهصورت اختصاصی معرفی کنیم و علاوهبر بررسی قابلیتهای جدید، بهبودِ راندمانِ آن را نسبت به نسلِ قبلیِ پاسکال زیرِ ذرهبین قرار دهیم.
RTX بهجای GTX
انویدیا این بار برخلافِ سالهای گذشته، محصولاتِ پرچمدارِ نسلِ جدید را با پیشوندِ RTX معرفی کرد. نام اختصاریِ RTX از فناوری جدیدِ انویدیا برای پردازش گرافیکی با روشِ Real-Time Ray Tracing (پرتویابی یا رهگیریِ پرتو در زمانِ واقع) یا همان Ray Tracing extension گرفته شده که همزمان با افزونهی جدید دایرکت ایکس به نام DirectX Raytracing معرفی شد. مشخصا RTX بهمعنی اضافه شدنِ عناصرِ ساخته شده با روشِ Ray Tracing به گرافیک رایج بازیهای ویدیویی است که با تکنیکِ rasterization تولید میشوند. تکنیک Ray Tracing روش واقع گرایانهتری برای خلق محیط و اشیاء است که تا به حال بیشتر برای ایجاد جلوههای ویژه در فیلمهای سینمایی به کار گرفته شده است. این پردازشها بهدلیلِ پیچیدگی و سنگینیِ کار بهصورت آفلاین و در شبکهای از کامپیوترهای قدرتمند یا رندر فارمها و در زمانی طولانی انجام میشد.
از نظر تاریخی، سخت افزارهای کامپیوتری تاکنون آنقدر سرعت نداشتهاند که قادر به پردازش گرافیکِ بازیها بهصورت Real-time و با تکنیک Ray Tracing باشند، اما این مهم حالا قرار است به کمک سختافزارِ معماری تورینگ و واحدهای پردازش قدرتمندِ آن به بازیهای بیشتری راه پیدا کند که از نظر Nvidia میتواند بهعنوان انقلابی در سختافزارِ گرافیکیِ پیسیها بعد از معرفی واحدهای پردازشی CUDA در ده سال قبل محسوب شود.
تورینگِ بزرگ: TU102
بزرگترین تراشهی ساخته شده براساس تورینگ، TU102 مساحتی بالغ بر ۷۵۴ میلیمتر مربع دارد که در قلبِ GeForce RTX 2080 Ti قرار داده شده است. تعدادِ ۱۸.۶ میلیارد ترانزیستورِ تشکیلدهندهی آن با فناوریِ ساخت ۱۲ نانومتریِ کارخانهی TSMC که 12nm FinFET نامگذاری شده تولید شدهاند که یک بهبودِ تراکمِ آشکار را نسبت به فناوری قبلیِ ۱۶ نانومتری منعکس میکند.
در مقامِ مقایسه با بزرگترین تراشهی ساخته شده با معماری پاسکال که GP102 بکار گرفته شده در GTX 1080 Ti بود، تراشهی TU102 به اندازهی ۶۰ درصد بزرگتر است و تعداد ترانزیستورهای آن هم ۵۵ درصد بیشتر است. اما این بزرگترین تراشهی ساخته شده توسط انویدیا نیست، چرا که پرچمدارِ تورینگ زیر سایهی تراشهی عظیمِ GV100 از نسلِ ولتا با ۲۱.۱ میلیارد ترانزیستور و مساحتِ ۸۱۵ میلیمترِ مربع قرار میگیرد. GV100 تراشهای بود که در سال ۲۰۱۷ با تمرکز بر برنامههای کاربردی در دیتاسنترها معرفی شد و هنوز هم میتوان آن را در کارتِ Titan V یافت.
TU102 بازارِ هدفِ متفاوتی را نسبت به GV100 نشانه گرفته است و در نتیجه فهرستی از منابع برای مطابقت با آن تدارک دیده شده است. درحالیکه برخی از عناصرِ تورینگ از معماری ولتا قرض گرفته شدند، بخشهایی از این معماری که یا برای گیمرها منفعتی نداشتند یا برای سیستمهای رومیزی مقرونبهصرفه نبودند، به کلی از این طراحی حذف شدند.
برای مثال هر واحدِ Streaming Multiprocessor که به اختصار آن را SM مینامیم، در تراشهی Volta شاملِ ۳۲ واحدِ پردازشیِ FP64 برای تسریعِ محاسبات اعشاری با دقت دو برابر میشد که در نتیجه به تعداد ۲۶۸۸ هستهی پردازشی برای FP64 در کل تراشهی GV100 بالغ میشد. ولی این واحدها در بازیها واقعا کاربردِ خاصی ندارند و فضای زیادی از سطحِ تراشه را هم اشغال میکنند، در نتیجه انویدیا این قسمت را حذف کرده و تنها دو واحد از FP64 را برای هر SM باقی گذاشته است. نتیجه این شده که راندمانِ TU102 در محاسباتِ FP64 برابر با ۱⁄۳۲ از نرخِ راندمان FP32 در آن است و تنها تعدادِ کافی برای سازگاری با نرم افزارهایی را که به عملکردِ این واحد وابستگی دارند در تراشه باقی گذاشته است. بهطور مشابه، ۸ کنترلرِ حافظهی ۵۱۲ بیتی که به ۴ پشتهی حافظهی HBM2 در GV100 متصل بودند، برای تولید بسیار گران تمام میشدند که با تراشههای GDDR6 ساختِ شرکتِ میکرون جایگزین شدند. به این ترتیب راهکارِ ارزانتری مهیا شد که در عینِ حال میتواند ارتقای پهنای باندِ بزرگی نسبت به مدلهای پیشینِ مبتنی بر پاسکال در اختیار قرار دهد.
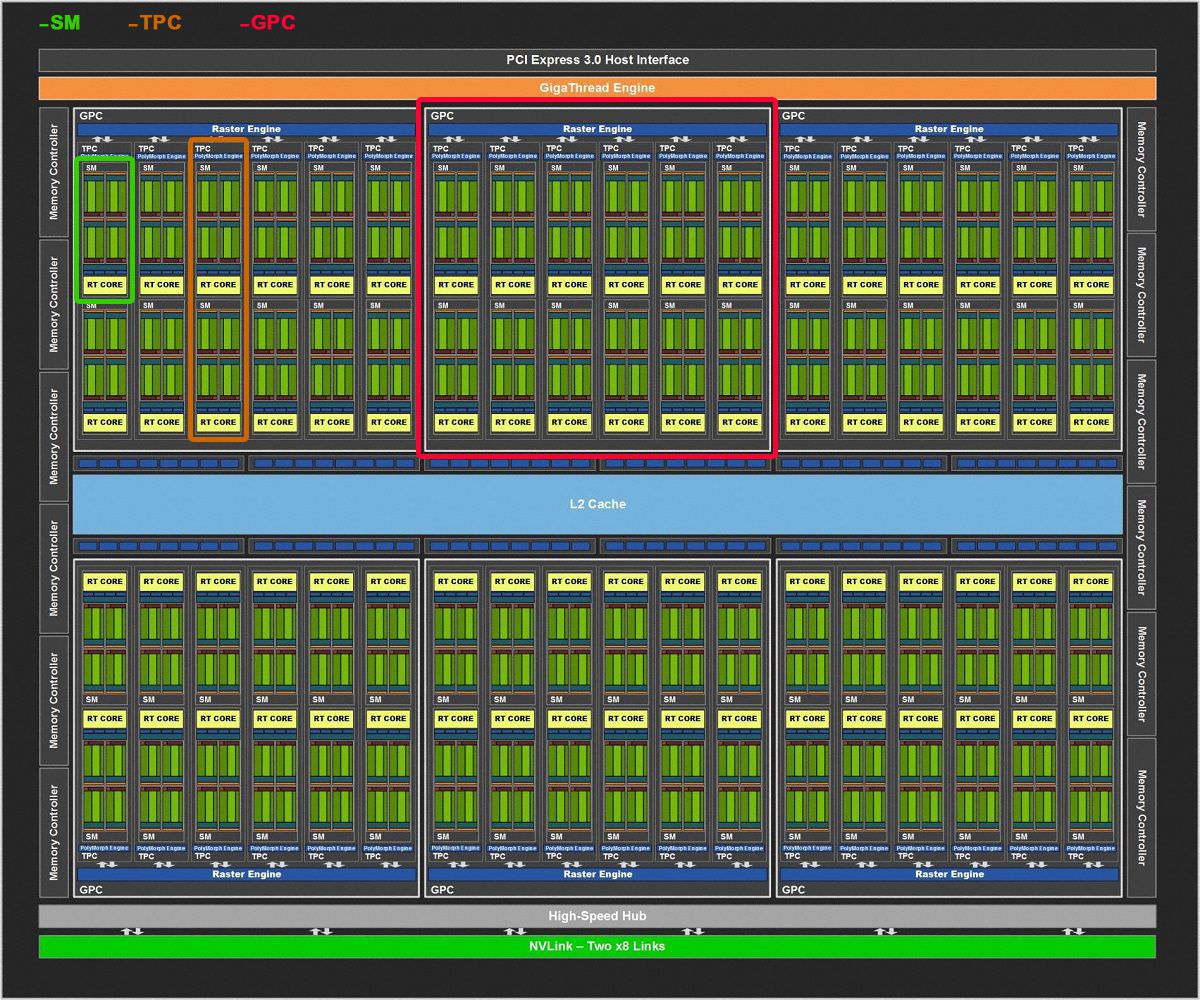
یک پردازندهی کاملِ TU102 شاملِ شش کلاسترِ پردازشِ گرافیکی یا GPC میشود که هر GPC هم به نوبهی خود از یک Raster Engine و شش کلاسترِ پردازشِ بافت یا TPC تشکیل شده است. هر TPC هم از یک PolyMorph Engine (خط لولهی پردازش هندسی با تابعِ ثابت) و ۲ واحدِ SM ساخته میشود. در داخلِ هر SM هم میتوان ۶۴ هستهی CUDA، تعدادِ ۸ هستهی Tensor، یک هستهی RT برای ray tracing، تعدادِ ۴ واحد بافت، ۱۶ واحدِ load/store، میزانِ ۲۵۶ کیلوبایت فضای فایل رجیستر، ۴ حافظهی کشِ سطحِ صفر یا L0 برای دستورالعمل و ۹۶ کیلوبایت حافظهی کشِ سطح یک یا L1 یا ساختارِ حافظهی اشتراکی را مشاهده کرد.
اگر تمامِ ارقامِ فوق را محاسبه کنید، میتوان یک تراشهی گرافیکی با ۷۲ واحدِ SM، تعدادِ ۴۶۰۸ هستهی CUDA، تعداد ۵۷۶ هستهی Tensor، همچنین ۷۲ هستهی RT، تعدادِ ۲۸۸ واحدِ بافت و ۳۶ موتور PolyMorph را بهدست آورد.

افزایشِ راندمان
انویدیا تلاشِ زیادی را در بازطراحیِ معماریِ تورینگ برای بهبود راندمان به ازای هر هسته کرده است. برای شروع، تورینگ پشتیبانی از اجرای همزمانِ دستورالعملهای محاسباتیِ FP32 و عملیاتِ INT32 را از ولتا به ارث برده است. FP32 بیشترین حجمِ پردازشی در واحدهای سایهزن (Shader) را تشکیل میدهد و INT32 هم برای عملیاتی نظیرِ آدرسدهی، گرفتنِ دادهها، ماکزیمم و مینیمم اعشاری، مقایسه و مانندِ آن استفاده میشود. این قابلیت بیشترینِ نقشِ افزایشِ راندمان در تورینگ نسبت به پاسکال را مرهونِ خود کرده است.
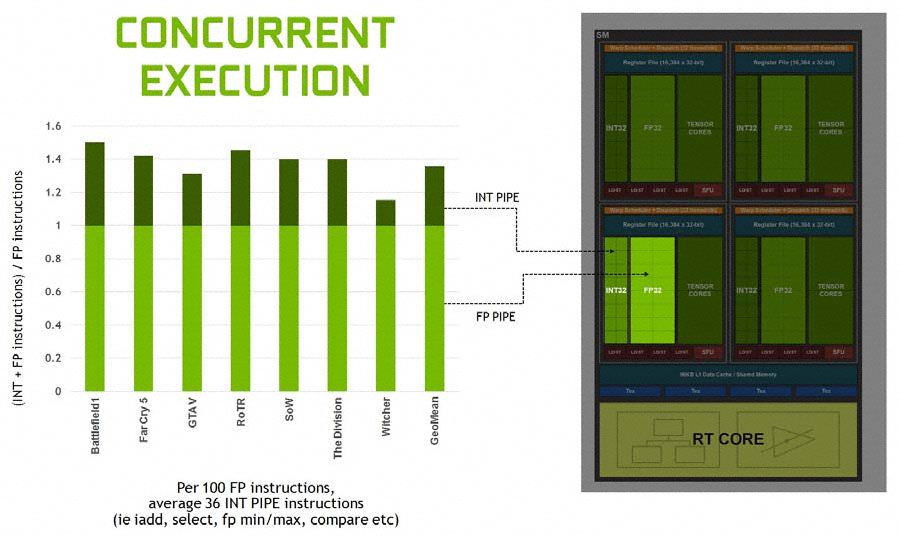
در نسلهای گذشته، دستورالعملهایی از انواعِ متفاوت نمیتوانستند همزمان اجرا شوند که این خود باعثِ بیکار ماندنِ خطِ لولهی اعشاری در هنگامِ اجرای دستورالعملهای غیرِ اعشاری میشد. معماریِ ولتا بهدنبالِ تغییرِ این رویه با ساختنِ خطِ لولههای مجزا برای هر یک از آنها برآمد. به این ترتیب بازدهی اجرای دستورها افزایش پیدا کرد و این مهم با تغییر در ترکیبِ ساختاریِ هر واحدِ SM یا Streaming Multiprocessor ممکن شد.
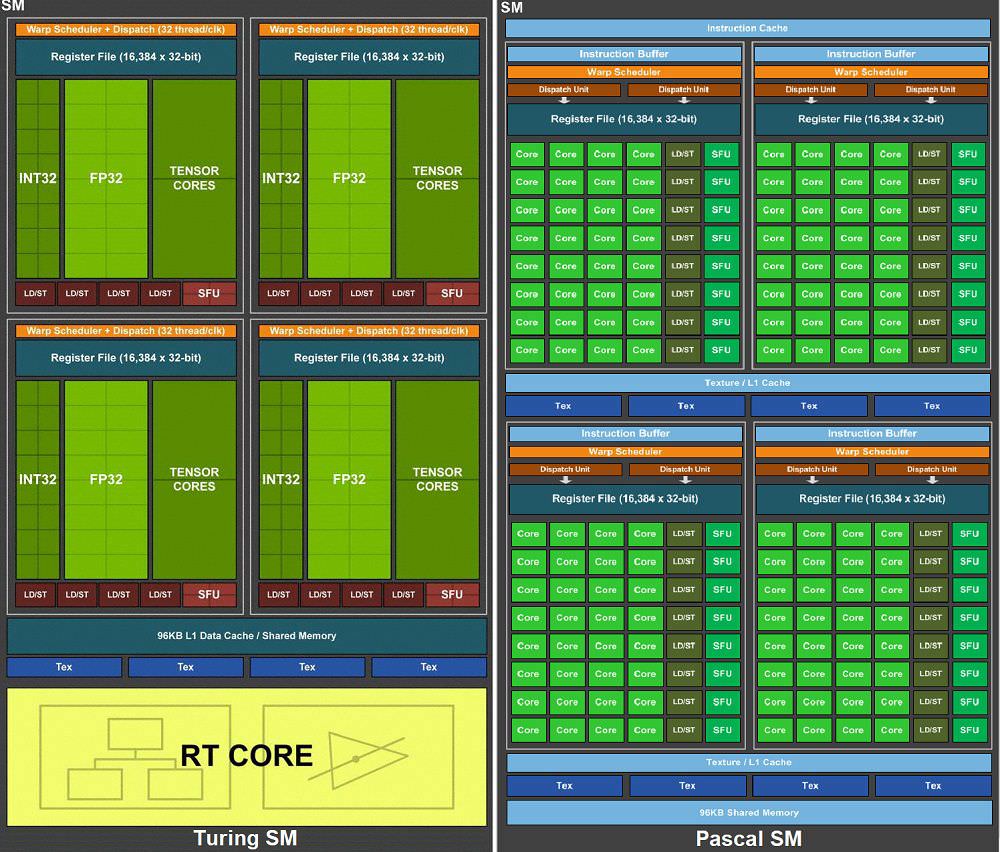
انعطافِ تورینگ از داشتنِ دو برابر واحدِ زمانبندِ بیشتر (scheduler) نسبت به پاسکال است که اکنون به یک زمانبند به ازای هر ۱۶ هستهی CUDA رسیده است، درحالیکه در پاسکال یک زمانبند به ازای هر ۳۲ واحدِ CUDA بود. افزایش و یکپارچه سازیِ ظرفیتِ حافظههای کشِ L1 به ازای هر SM و L2 که اکنون به دو برابرِ میزانِ تعبیه شده در معماری پاسکال رسیده است هم نقشِ کلیدی در بهبودِ راندمان بازی میکند. بهلطفِ این تعادلِ بهبود یافته، معماری تورینگ اکنون میتواند از منابع استفادهی بهتری داشته باشد.
واحد Tensor
اگرچه معماری ولتا تغییراتِ عمدهی زیادی را در مقایسه با معماری پاسکال در بر داشت، اضافه شدنِ هستههای Tensor، بزرگترین نشانه از هدفِ نهایی تراشهی GV100 بود: شتابدهیِ ماتریسی ۴×۴ از عملیات با ورودیهای FP16 (فرمتِ عددِ اعشاری با استفاده از ۱۶ بیتِ باینری) که اساسِ استنتاج و آموزشِ شبکههای عصبی را تشکیل میدهد.
درست مانند ولتا، معماری تورینگ هم ۸ هستهی Tensor به ازای هر SM در اختیار دارد. البته TU102 شامل SM-های کمتری نسبت به GV100 است و خودِ GeForce RTX 2080 Ti هم واحدهای فعالِ کمتری از TU102 را در مقایسه با TItan V در اختیار دارد (۶۸ دربرابر ۸۰). در نتیجه این کارت در کل ۵۴۴ هستهی Tensor دارد که ۹۶ واحد کمتر از ۶۴۰ هستهی کارت Titan V است. اما نکتهی مهم این است که هستههای Tensor در TU102 به شکلِ متفاوتی از هستههای ولتا پیادهسازی شدهاند و عملیاتِ INT4 و INT8 را هم پشتیبانی میکنند که البته دلیلِ موجهی دارد: GV100 ساخته شده بود که شبکههای عصبی را درک کند و یاد بگیرد، درحالیکه TU102 یک تراشهی گیمینگ است و قرار است توانایی استفاده از الگوریتمهای فرا گرفته شده برای استنتاج را هم داشته باشد. انویدیا ادعا دارد که هستههای Tensor در TU102 تا ۱۱۴ ترافلاپس برای عملیات FP16، تا ۲۲۸ میلیارد عملیات برای INT8 و تا ۴۵۵ میلیارد عملیات برای INT4 ارائه میکنند.
بیشترِ برنامههای فعلی انویدیا برای واحدِ Tensor پیرامونِ گرافیکِ عصبی (neural graphics) سیر میکند. با این همه این شرکت در موردِ کاربردهای دیگرِ یادگیری عمیق در کارتهای گرافیکِ رومیزی هم در حال تحقیق است. برای نمونه دشمنانِ هوشمند میتوانند به کلی رویکردِ گیمرها در نبردهای نهایی (Boss Fights) در بازیها را دگرگون کنند. درکِ گفتار، تشخیصِ صدا، ترمیمِ هنری، تشخیصِ تقلب و انیمیشنِ کاراکترها همه حوزههایی هستند که هوش مصنوعی در آنها کاربرد دارد یا انویدیا در آنها زمینههایی را برای کاربردِ مناسب میبیند.
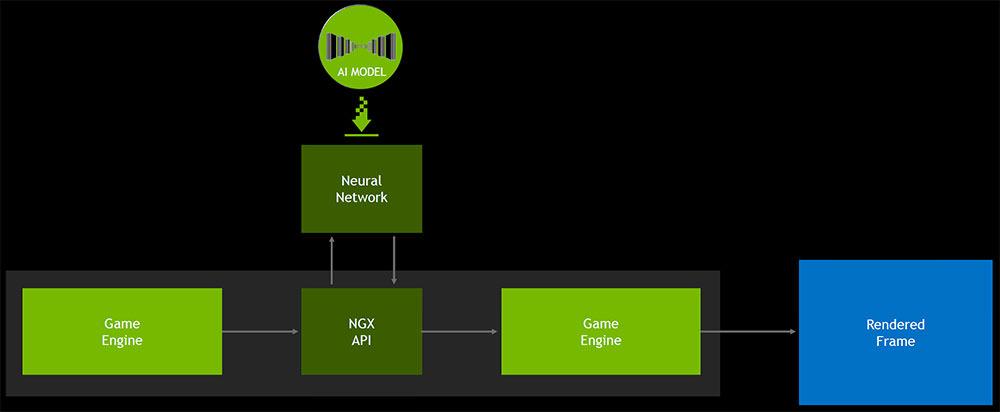
اما البته GeForce RTX روی DLSS یا همان Deep Learning Super Sampling تمرکز دارد. شیوهی پیادهسازیِ DLSS به پشتیبانیِ سازنده ازطریقِ NGX API انویدیا نیاز دارد. انویدیا میگوید که مشارکت در این طرح آسان است و قبلا هم فهرستی از بازیهایی را که برای پشتیبانی از DLSS برنامهریزی شدهاند منتشر کرده است تا اشتیاقِ این صنعت را به کاری که DLSS با کیفیتِ تصاویر میکند به رخ بکشد. احتمالا سهولتِ کار برای بازیسازان به این دلیل است که بخشِ اعظمِ کار بر عهدهی خودِ انویدیا است. این شرکت تصاویرِ واقع گرایانه از بازی را با بالاترین کیفیتِ ممکن تولید میکند. این کار ازطریقِ بهرهگیری از نمونههایی با رزولوشنِ فوقِ العاده بالا در هر فریم، یا تعداد زیادی فریم که با هم ترکیب شدهاند میسر میشود. سپس به یک مدلِ هوش مصنوعی در سرورِ SaturnV (دارای ۶۶۰ نود DGX-1) تعلیم داده میشود که تا جای ممکن نزدیکترین تصاویرِ به تصاویرِ واقع گرایانه با کیفیتِ پایینتر را تشخیص دهد. این مدلهای AI ازطریقِ درایورِ انویدیا دانلود شده و در هستههای Tensor روی هر کارت گرافیک GeForce RTX قابلِ دسترسی خواهند بود. انویدیا میگوید که حجم این مدلهای AI براساس مگابایت قابلِ اندازه گیری خواهد بود که در نتیجه آنها را نسبتا سبک وزن و کم حجم میکند.
انویدیا تایید کرده که ویژگیهای NGX در GFE تنیده شدهاند، اما در سطحِ درایور هم قابلِ دسترسیِ مستقیم توسطِ بازیها خواهند بود. اگر این نرمافزار یک تراشهی گرافیکی بر مبنای تورینگ را شناسایی کند، یک پکیج به نام NGX Core را دانلود میکند که بازیها یا اپلیکیشنهای مرتبط با NGX را تشخیص میدهد. اگر موردِ مطابقی روی سیستم پیدا شود، NGX Core هرگونه اطلاعاتِ مربوطبه شبکههای عصبی و یادگیریِ عمیق را برای استفادهی بعدی بازیابی میکند.

تصویری از دموی پردازش شده با تکنیکِ TAA برای Anti-Aliasing، به گسستگیِ متن توجه کنید

محو شدگیِ متن با تکنیکِ DLSS در همان صحنه برطرف شده است و کیفیتِ به مراتب بالاتری دارد
آیا DLSS ارزش این تلاش را خواهد داشت؟ ما یک نمونه از DLSS در دموی Infiltrator ساختهی Epic را دیدهایم که بسیار خوب به نظر میرسید. اما تضمینی نیست که انویدیا بتواند همین سطح از نتایج را برای هر بازی دیگری فارغ از سبک، سرعت و جزئیاتِ محیطیِ آن بهدست آورد. حداقل تا اینجای کار، نمونههای ابتداییِ پیاده شده از DLSS در بازیهای BattleField V و Metro Exodus ناامید کننده بودند که در بروز رسانیهای بعدی کیفیتِ به مراتب بهتری پیدا کردند و در بسیاری موارد هم از تصاویرِ اصلی قابل تشخیص نیستند یا شارپتر به نظر میرسند. کمی پیشتر DLSS برای بازیهای Anthem و Shadow of the Tomb Raider هم عرضه شد که براساسِ دقتِ خروجی تصویر، کیفیت عملکردِ آن روی تصاویر متفاوت بود، اما در عینِ حال افزایشِ راندمانِ خوبی را به همراه داشت.
چیزی که در مجموع میدانیم این است که DLSS یک یادگیری پیچشی (تعریفی در شبکهی عصبی پیچشی یا convolutional neural network: ردهای از شبکههای عصبیِ عمیق هستند که معمولاً برای انجام تحلیلهای تصویری یا گفتاری در یادگیریِ ماشین استفاده میشوند) بهصورتِ real-time و رمزگذارِ اتوماتیکی است که از تصاویری که ۶۴ برابر نمونه برداری شدهاند، استخراج شده است. درواقع به DLSS ازطریقِ رابطِ نرمافزاری NGX API یک فریم با دقتِ معمولی میدهند و بهجای آن یک نسخهی با کیفیتِ بالاتر از همان فریم را برمیگرداند.
مزیتِ استفاده از DLSS این است که میتواند با کاستن از بارِ کاریِ سایهزنها یا همان Shader-ها به افزایشِ راندمان کمک کند. تورینگ میتواند خروجیِ با کیفیتتری از نمونههای ورودی در مقایسه با یک الگوریتمِ پس پردازش (post-processing) مانندِ Temporal Anti-Aliasing یا همان TAA تولید کند. با اینکه تورینگ زمانِ قابل توجهی را صرفِ اجرای شبکهی عصبی میکند، میزانِ صرفهجویی شده به خاطرِ کارِ کمتر در هستههای سایهزن قابلتوجهتر است. همچنین با استفاده از DLSS، از عارضهها و محو شدگیهایی که گاهی اوقات با بکارگیریِ تکنیکِ TAA ایجاد میشوند هم اجتناب میشود. انویدیا قبلا فهرست بازیهایی که از فناوری RTX و DLSS پشتیبانی میکنند را اعلام کرده بود.

بهعنوانِ نمونه، بررسیِ دیجیتال فاندری با آخرین بروز رسانی بازیِ Anthem نشان داد که کیفیتِ خروجی DLSS باعثِ حذفِ برخی جزئیاتِ بافتها میشود که شاید در جریانِ بازی قابلِ تشخیص نباشد. اما در بسیاری موارد مشابه با پردازشِ تصویر در دقتِ 1800p و Upscale کردنِ آن به رزولوشن 4K است، هر چند که در برخی موارد مثل بافتهای شفاف (امواج آب) و برخی افکتها (مانند Bloom) بهتر از پردازش در دقتِ 1800p و حتی رزولوشنِ Native یا اصلیِ 4K عمل میکند.
واحد RT
مقالهی مرتبط
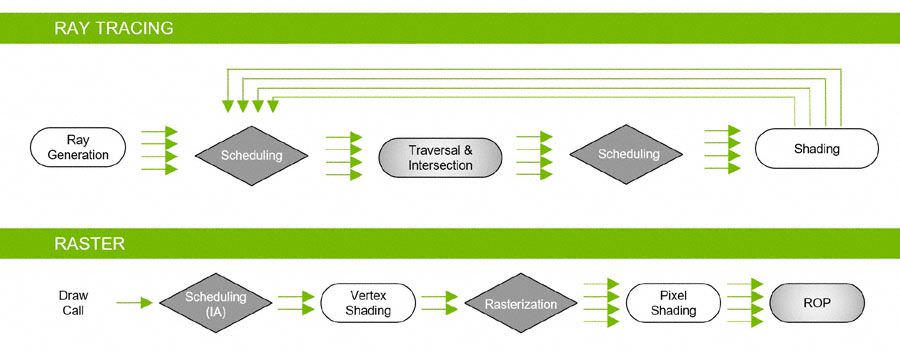
فراتر از محدوهی آنچه که معماری ولتا به آن رسیده بود و احتمالا امیدوار کنندهترین بخش در داستانِ تورینگ، هستههای RT برای محاسباتِ رهگیری پرتو (Ray Tracing) هستند که به انتهای هر واحدِ SM در تراشهی TU102 ضمیمه شدهاند. هستههای RT انویدیا لزوما شتابدهندههای تک منظورهای برای عملیاتِ Bounding Volume Hierarchy یا اختصارا BVH و همینطور به منظورِ تشخیصِ برخورد پرتو با مثلثها هستند (مثلث کوچکترین واحدِ تشکیلدهندهی چند ضلعیهایی است که در گرافیکِ سهبعدی برای ترسیمِ اشکالِ مختلف استفاده میشوند، زیرا یک مثلث هرگز نمیتواند غیر مسطح باشد. هر چندضلعی با داشتنِ بیشتر از ۳ راس به مثلث قابل تجزیه است). قبل از این طی مقالهای جداگانه به Ray Tracing و کارکرد و تاثیرِ آن در بازیها پرداخته بودیم، اما حالا به شیوهی پیادهسازی و پردازشِ فنی آن در هستههای RT خواهیم پرداخت.




مقالهی مرتبط
بهطور خلاصه، BVH جعبههای فرضیِ هندسی را در صحنهی داده شده شکل میدهد. این جعبهها کمک میکنند که موقعیتِ مثلثهای قرار گرفته در مسیرِ پرتو را در طیِ یک ساختارِ درختی (مطابق شکلهای بالا - روی تصاویر کلیک کنید تا نمونهی بزرگتر بارگذاری شود) مرحله به مرحله محدودتر کنند. هر زمان که یک مثلث در یک جعبهای پیدا شود، آن جعبه به جعبههای کوچکتر تقسیم میشود و این کار تا زمان پیدا شدن جعبهی نهایی ادامه پیدا میکند. جعبهی نهایی هم جعبهای است که قابلِ تقسیم به مثلثها باشد. بدونِ BVH-ها، یک الگوریتم مجبور بود تا تمامِ صحنه را در جستجوی مثلثها پیمایش کند و هزاران سیکلِ پردازشی برای آزمایشِ برخوردِ یک پرتو با هر مثلث از بین میرفت.
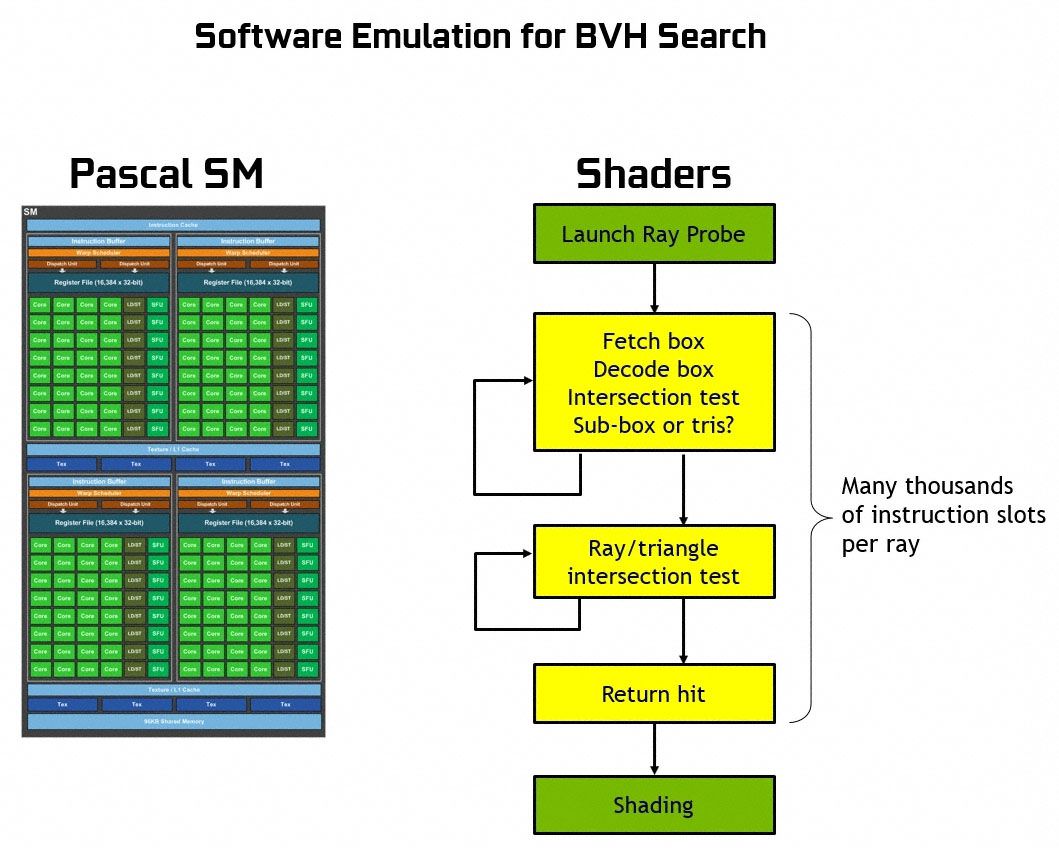
امروزه اجرای این الگوریتم با استفاده از لایههای بازگشتی در API یا رابطِ برنامهسازیِ Ray tracing اضافه شده به دایرکت ایکس 12 مایکروسافت بهصورت کامل امکانپذیر است. در این شیوه، از هستههای مرسومِ سایهزن برای شبیهسازیِ تکنیکِ رهگیریِ پرتو روی دستگاههای بدون پشتیبانیِ سختافزاری از Ray tracing استفاده میشود. بهعنوان نمونه روی تراشههای گرافیکی پاسکال، اسکن به روشِ BVH روی هستههای قابل برنامهریزی اتفاق میافتد که هر جعبه را دریافت، رمزگشایی و برای وجود یا عدمِ وجودِ تلاقی با پرتو آزمایش میکنند و تعیین میکنند که جعبهی کوچکتر یا مثلث در داخل آنها وجود دارد یا خیر. این پروسه تا پیدا شدنِ محلِ تلاقی پرتو با مثلثِ نهایی تکرار میشود. همانطور که ممکن است تصور کنید، این عملیات برای اجرا در سطحِ نرمافزاری بسیار پر هزینه و زمانبر است و از اجرای روانِ تکنیکِ رهگیریِ پرتو بهصورتِ Real-time روی پردازندههای گرافیکیِ امروزی جلوگیری میکند.
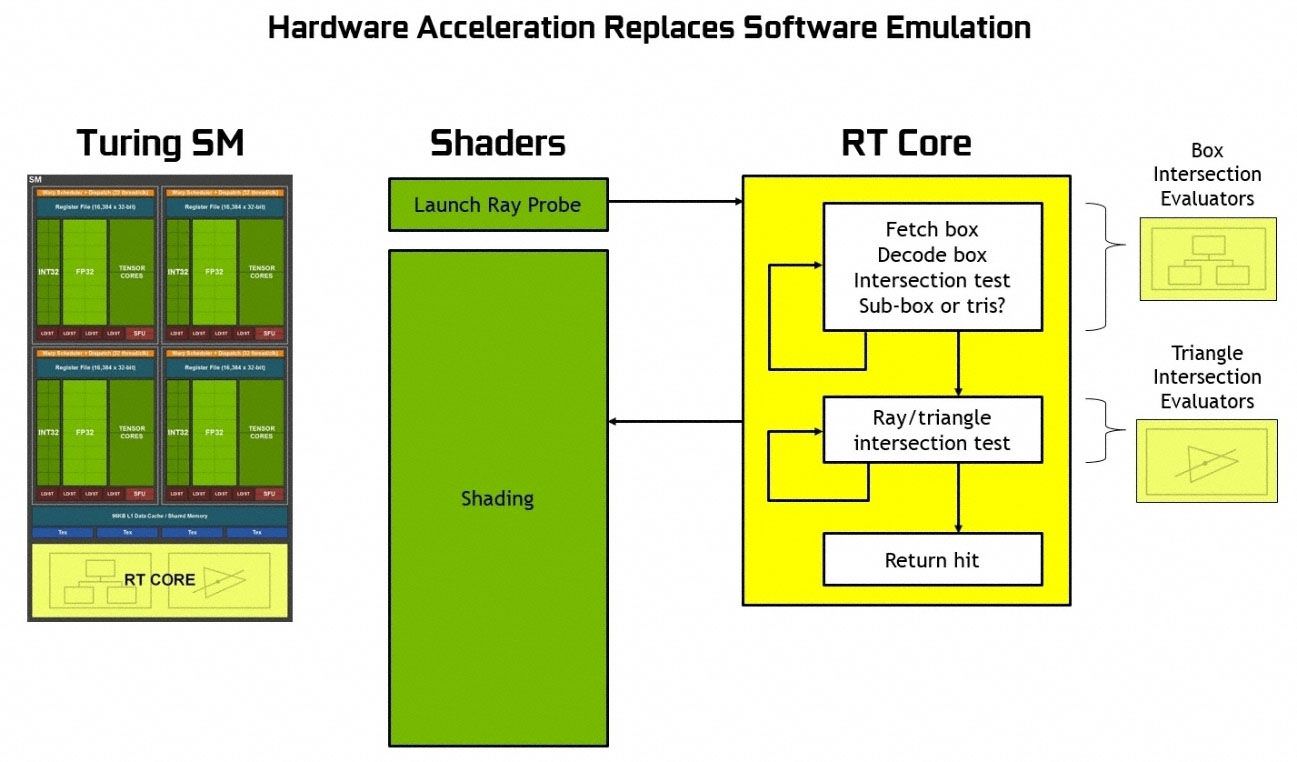
با ساختنِ شتابدهندههای تک منظوره برای مراحلِ آزمایشِ تلاقی با جعبه و مثلث، واحدِ SM یک پرتو را به کمکِ یک سایهزنِ مولدِ پرتو به صحنه میتاباند و ادامهی کار را به گذرگاهِ شتابدهنده در هستهی RT واگذار میکند. در نتیجه تمامِ ارزیابیهای مربوطبه تلاقی یا برخورد بسیار سریعتر اتفاق میافتد و منابعِ دیگرِ واحدِ SM در معماری تورینگ (شکلِ بالا) برای کارهای معمولِ این واحد به روشِ مرسومِ rasterization آزاد میشود.
بهگفتهی انویدیا، یک GeForce GTX 1080 Ti میتواند حدودِ ۱.۱ میلیارد پرتو در ثانیه را با استفاده از هستههای CUDA در حالتِ نرمافزاری پردازش کند. در مقایسه، GeForce RTX 2080 Ti میتواند حدودِ ۱۰ میلیارد پرتو در ثانیه را با بهرهگیری از تواناییِ ۶۸ هستهی RT محاسبه کند. لازم به یادآوری است که مقادیرِ راندمان بر حسبِ Gigarays، براساسِ میانگینِ هندسیِ بهدست آمده از خروجیهای متعدد محاسبه و اعلام شده است.
Variable Rate Shading
اضافه بر بهینهسازیِ روشی که تورینگ دادههای هندسی را پردازش میکند، انویدیا همچنین از مکانیزمی برای انتخابِ کیفیتِ سایهزنی یا shading پشتیبانی میکند. در این شیوه بلاکهایی متشکل از ۱۶ در ۱۶ پیکسل در قسمتهای مختلفِ صحنه با نرخهای متفاوت سایهزنی میشوند تا راندمان را افزایش دهند. بهطور طبیعی سختافزار هنوز هم میتواند هر پیکسل را در الگوی ۱×۱ سایهزنی کند. اما این معماری استفاده از گزینههای دیگری مثل الگوهای ۲×۱، ۱×۲ و ۴×۴ را هم تسهیل میکند.

Full-rate Shading یا سایهزنی با نرخِ کامل (تصویرِ بالا)

Content-adaptive shading یا سایهزنیِ وابسته به محتوا - کدگذاری شده با رنگ

Content-adaptive shading یا سایهزنیِ وابسته به محتوا - خروجی نهایی
انویدیا مواردِ استفادهی متعددی را برای سایهزنی با نرخِ متغیر (Variable Rate Shading) در عمل معرفی کرده است. اولین کاربرد در content-adaptive shading یا سایهزنیِ سازگار با محتوا است، جایی که قسمتهای دارای جزئیاتِ کمتر در صحنه تغییرِ زیادی نمیکنند و میتوانند با نرخِ کمتری سایهزنی شوند.

motion-adaptive shading هم کاربردِ جالبِ دیگری از فناوریِ سایهزنی با نرخِ متغیرِ انویدیا است که در آن آبجکتهای در حالِ حرکت در دقت پایینتری نسبت به موضوعی که روی آن تمرکز داریم به نظر میرسند. بازیسازان میتوانند نرخِ سایهزنی را براساسِ بردارِ حرکتیِ هر پیکسل به دلخواه تعیین کنند و الگوهای همسان با مثالی را که در استفادهی اولی از این روش دیدیم پیادهسازی کنند. در کارتهای گرافیکِ نسبتا ضعیف و بازیهای سنگینتر دستیابی به ۲۰ درصد راندمانِ بالاتر با استفاده از این روش امکانپذیر خواهد بود. مهمتر اینکه افتِ کیفیتِ تصویریِ محسوسی هم نخواهیم داشت. استفاده از این فناوری مستلزمِ گنجانده شدنِ آن در API است و انویدیا برای فعال شدنِ پشتیبانی دایرکت ایکس از سایه زنی با نرخِ متغیر در حالِ کار با مایکروسافت بود تا سرانجام مایکروسافت رسما اعلام کرد که این قابلیت یا به اختصار VRS را به کتابخانهی استانداردِ DirectX 12 اضافه خواهد کرد. اما همزمان انویدیا عملکردِ adaptive shading را در کیتِ توسعهی نرمافزارِ NVAPI در اختیار قرار خواهد داد که دسترسیِ مستقیم به قابلیتهای تراشهی گرافیکی را فراتر از بازهی کاریِ دایرکت ایکس و OpenGL فراهم خواهد کرد.
حافظهی گرافیکِ GDDR6
تفاوت دیگر بین نسل پاسکال و نسلهای جدیدترِ ولتا و تورینگ حافظهی گرافیکی است. به نظر میرسید که حافظههای پرسرعتِ HBM2 برای محصولات تجاریِ ردهی مصرفکننده پرهزینه و گرانقیمت باشند و به همین علت انویدیا از آنها در مدلهای مخصوص بازی استفاده نکرد. در حال حاضر صنعتِ کارت گرافیک استفاده از GDDR6 را به HBM2 ترجیح میدهد، چرا که تولید و اضافه کردن آنها به تراشههای گرافیکی آسانتر و کم هزینهتر است و با فناوریِ کنونی، راندمانِ مشابه یا حتی بالاتری را نسبت به HBM2 عرضه میکنند. تراشههای مبتنی بر معماریِ تورینگ با حافظههای ۱۴ گیگابیت بر ثانیهی GDDR6 همراه میشوند. سازندگانِ DRAM انتظار دارند که در آینده با GDDR6 به سرعت ۱۸ گیگابیت بر ثانیه و بالاتر هم دسترسی پیدا کنند.
RTX 2080 Ti
RTX 2080 Ti یک تراشهی کاملِ TU102 را در خود جای نداده، چرا که یا راندمانِ خطِ تولید برای تراشههای کامل احتمالا قابلِ قبول نبوده، یا تراشهی کامل برایِ کارتی از کلاسِ تایتان کنار گذاشته شده است. در RTX 2080 Ti دو واحد از TPC-ها، یکی از کنترلرهای ۳۲ بیتی حافظه و در نتیجه بخشی از ROP-ها و حافظهی کشِ L2 غیرفعال شدهاند.
مشخصات فنی
| GeForce | GTX 1080 | GTX 1080 Ti | RTX 2080 | AORUS GeForce RTX™ 2080 Ti XTREME |
| تراشهی گرافیکی | GP104-400-A1 | GP102-350-A1 | TU104-400 | TU102-300A |
| معماری | Pascal | Pascal | Turing | Turing |
| تعداد ترانزیستور | 7.2 Billion | 12 Billion | 13 Billion | 18.4 Billion |
| پروسهی ساخت | TSMC 16 nm | TSMC 16 nm | TSMC 12 nm | TSMC 12 nm |
| هستههای CUDA | 2560 | 3584 | 2944 | 4352 |
| واحدهای SMX | 20 | 28 | 24 | 32 |
| واحدهای ROPs | 64 | 88 | 64 | 88 |
| فرکانس پایهی تراشه | 1,607MHz | 1,506MHz | 1,482MHz | 1,348MHz |
| فرکانس توربوی تراشه | 1,733MHz | 1,683MHz | 1,582MHz | 1,770MHz |
| سرعت حافظه | 11.00Gbps | 11.00Gbps | 14.00Gbps | 14.00Gbps |
| اندازهی حافظه | 8GB GDDR5X | 11GB GDDR5X | 8GB GDDR6 | 11GB GDDR6 |
| عرض باند گذرگاه حافظه | 256bit | 352bit | 256bit | 352bit |
| پهنای باند حافظه | 320GB/s | 484GB/s | 448GB/s | 616GB/s |
| راندمان GigaRays | - | - | 8Giga Rays/s | 10Giga Rays/s |
| فناوری اتصالی | SLI | SLI | NVLink | NVLink |
| توان مصرفی | 180Watts | 250Watts | 215Watts | 250Watts |
| قیمت | ۵۰۰ دلار | ۷۰۰ دلار | ۶۹۹ دلار | ۹۹۹ دلار |

محتویاتِ بستهبندی
- کارت گرافیک (با وزن ۱۴۲۰ گرم)
- لوگوی متالیکِ AORUS
- کیتِ anti-sag (ضد خمیدگی) بهعنوان نگه دارندهی کمکی برای کارت گرافیکِ سنگین و مهارسازِ آن با قابلیتِ تنظیمِ ارتفاع

ویژگیهای اختصاصی
- بهرهگیری از طراحیِ مدار تغذیهی استثنایی ۱۶+۳ (۱۶ فاز برای GPU و ۳ فاز برای Memory)
- سیستمِ جدید خنککنندهی WINDFORCE Stack 3X، شاملِ سه فن ۱۰ سانتیِ WindForce با نورپردازی RGB به کمک LED-های تعبیه شده روی تیغههای هر فن
- فنهای Double Ball bearing و فن مرکزی که با کمی همپوشانی فنهای کناری برای پیشگیری از Air turbulence یا آشفتگیِ جریانِ هوا در جهتِ عکس میچرخد.
- دارا بودن ۷ خروجی ویدئویی در دو بلاکِ مجزا (اولی 3x HDMI + 1x Type-C ، دومی 3x DP + 1x HDMI + 1x Type-C)
- Back plate فلزی برای محافظت از پشتِ برد و دفعِ حرارتِ بهتر با لوگوی RGB برندِ AORUS که با ۳ پدِ حرارتی در محلِ قرار گیری تراشههای GDDR6 به پشتِ برد متصل است
- تراشهی گرافیکی با اورکلاکِ کارخانهای
- فرکانسِ ۱۷۷۰ مگاهرتز دربرابرِ فرکانسِ مرجعِ ۱۵۴۵ مگاهرتز برای تراشهی گرافیکی، فرکانسِ ۱۴۱۴۰ مگاهرتز برای حافظهی ۱۱ گیگابایتی
- تراشههای دستچین شده با فناوریِ Gunlet Sorting گیگابایت برای اطمینان از دارا بودنِ بالاترین حدِ اورکلاک حتی بیشتر از فرکانسِ اورکلاک کارخانهای
- تراشههای سری 300A که پسوند A نشاندهندهی اختصاصِ آنها به اورکلاک کارخانهای توسطِ انویدیا است. جالب توجه اینکه گیگابایت برای تولید یک کارت گرافیک رده حرفهای تا این حد، یک قدم جلوتر از سایر میگذارد و با دستچین کردنِ تراشههای گرانقیمتِ TU102 برای این کارت، درصدِ موفقیتِ گیمرها در اورکلاک بیشترِ این کارت را از مدلهای همردهی برندهای مشابه بیشتر میکند.

- هیت سینکِ Heat Pip direct touch که مستقیما حرارتِ GPU را با هیت پایپها به خنککنندهی بالا دستی منتقل میکند. ماسفتهای مدارِ تغذیه و تراشههای حافظهی GDDR6 هم مستقیما با خنککننده در ارتباط هستند تا دفعِ حرارتِ بهتر انجام شود.
- یکی از جذابترین طراحیهای ظاهری با بهرهگیری از نورپردازی RGB قابل آدرس دهی ازطریقِ نرمافزار RGB Fusion که افکتهای بینظیری را در بین تمام افکتهای RGB تولید میکند.
- ابعاد: طول ۲۹۰ میلی متر - عرض ۱۳۴.۳۱ میلیمتر - ارتفاع ۵۹.۹
- دو ورودی ۸ پین برقِ PCI Express با نشانگرهای LED برای اطمینان از اتصالِ صحیح به کابلهای برق و ورودیِ جریان. (منبع تغذیهی ۷۵۰ واتی توصیه میشود)
- کانکتورِ NVLink برای ارتباط با کارتهای گرافیک دیگر و استفاده از SLI
- نرمافزار Aorus Engine: در این ابزارِ اختصاصی علاوهبر تنظیماتِ رایج و مشابه با ابزارهای نرمافزاری کارتهای گرافیکی مثل دسترسی به تنظیمات فرکانس و ولتاژ و دور فن، امکانات کنترلی روی نشانگرهای LED هم اضافه شده است.
سیستم تست
- پردازنده: Intel Core i7 – 9700K OC to 5.0 GHz
- مادربرد/ حافظه: ASUS Z390-F Strix Gaming/ GSkill DDR4 3200Mhz 16GB
- سیستمعامل: ویندوز 10 نسخهی October Update با آخرین آپدیتها (1809- 17763.316)
- درایورها: انویدیا GeForce 418.91 WHQL و AMD Radeon Software Adrenalin Edition 19.2.2
کارتهای گرافیک
- GeForce GTX 1080 Ti 8GB
- GeForce GTX 1080 8GB
- GeForce GTX 1070 8GB
و البته کارت گرافیکِ AORUS GeForce RTX™ 2080 Ti XTREME
بنچمارکها
3DMARK 2013
راندمان دایرکت ایکس ۱۱
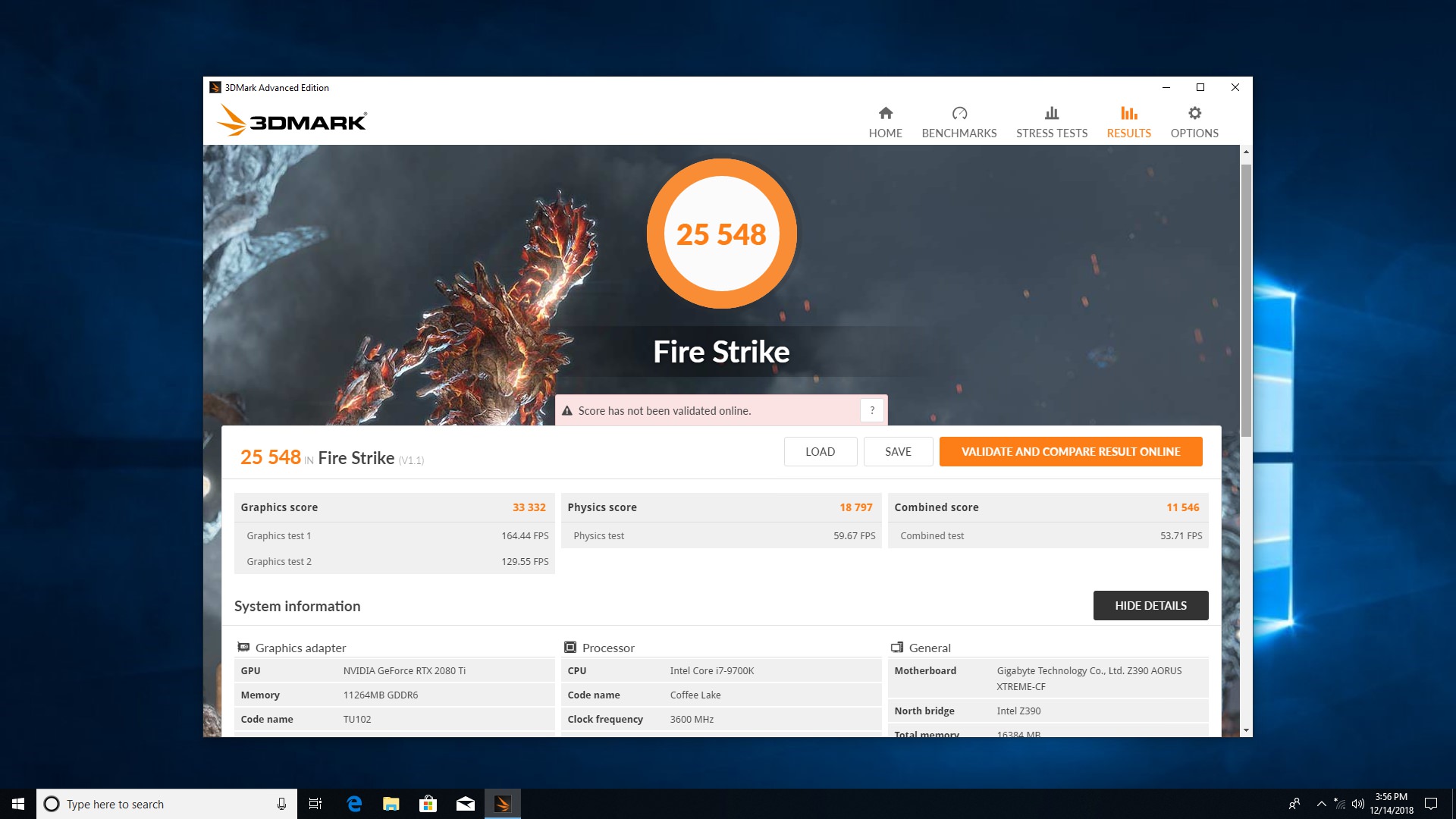
مثل همیشه برای شروع، در بنچمارکِ معتبرِ 3DMark 2013، آزمایش Fire Strike را روی کارتهای گرافیکی منتخب اجرا کردیم و با گرفتنِ امتیاز ۲۵۵۴۸، افزایش امتیازی حدود ۱۲ درصد را نسبت به GTX 1080 Ti تجربه کردیم. البته امتیازِ Graphics Score حدودِ ۱۹ درصد بهبودِ عملکرد را نشان میدهد. اما از بررسی کارت گرافیک GTX 1080 به خاطر داریم که کارت GTX 1080 در مقایسه با همردهی نسل کپلر یعنی GTX 980 با طرح مرجع، به میزان ۷۵ درصد امتیاز بالاتری را کسب کرده بود که پیشرفتی خیره کننده بود.
راندمان دایرکت ایکس ۱۲
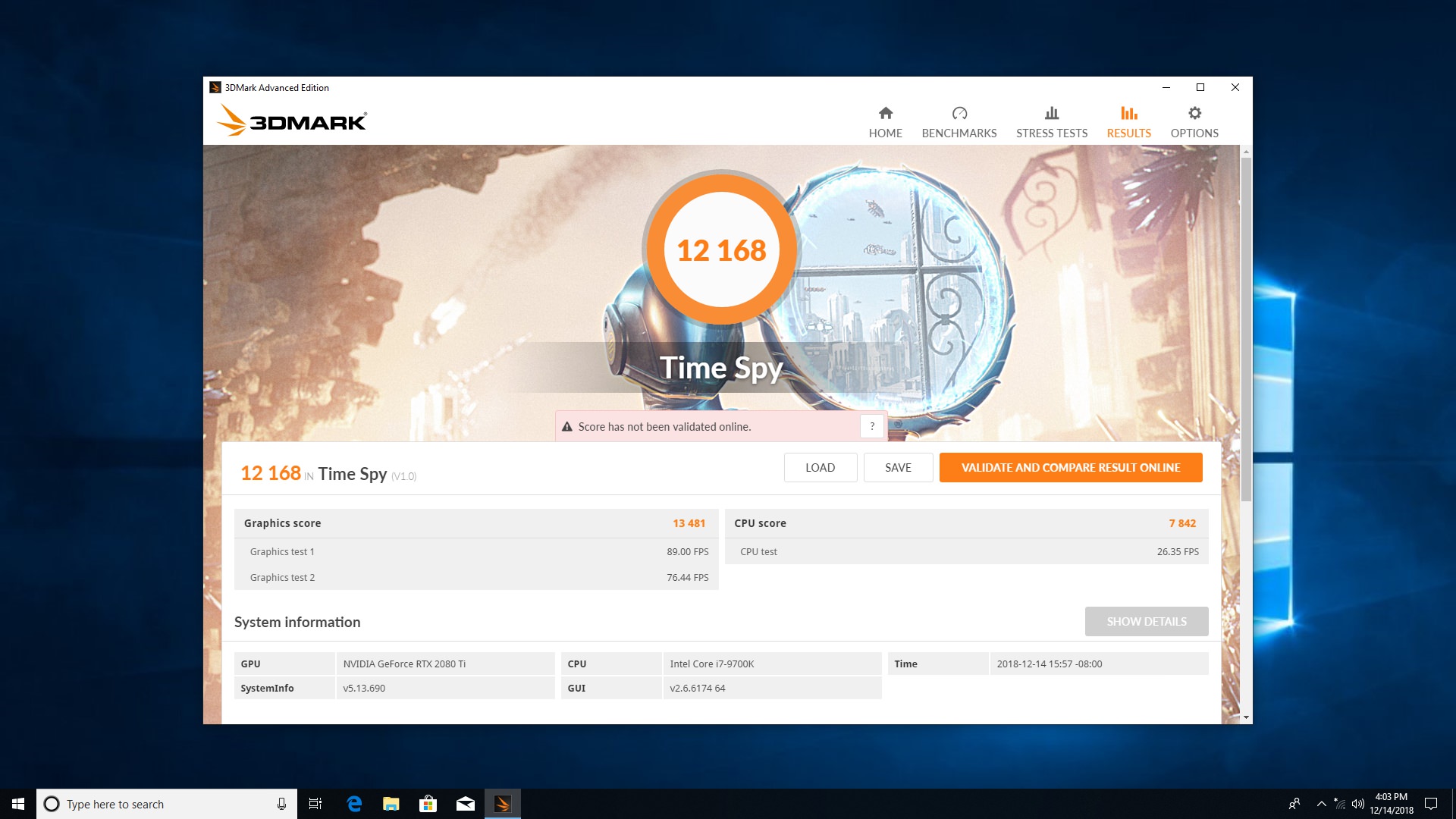
در آزمایش Time Spy که براساسِ دایرکت ایکس 12 ساخته شده، آمارِ بهدست آمده بسیار بهتر بود و توانستیم تا ۳۰ درصد راندمانِ بهتری را نسبت به GTX 1080 Ti اورکلاک شدهی گیگابایت بهدست آوریم که نتیجهی قابل توجهی بود. بنابراین باید انتظار داشت که بهبود راندمانِ تراشههای تورینگ در حالتِ دایرکت ایکس 12 بسیار بالاتر از دایرکت ایکس 11 باشد.
BattleField V
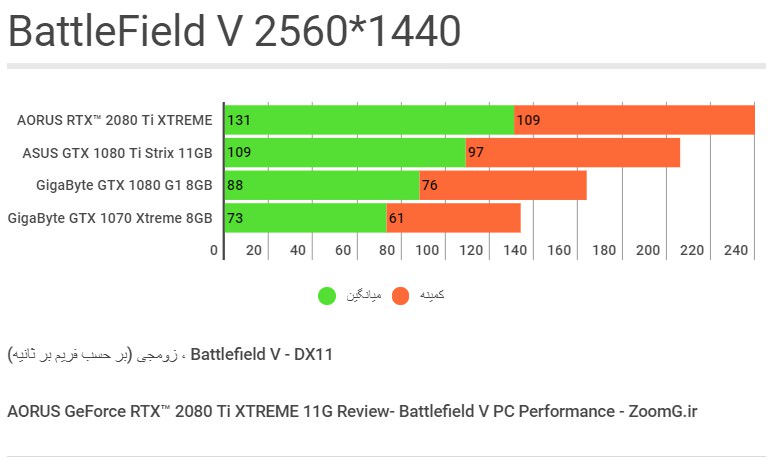
از آنجایی که بعید است کاربری بخواهد کارتِ گرانقیمت و قدرتمندی مثلِ RTX 2080 Ti را برای بازی با نمایشگرِ 1080p خریداری کند و حتی نمایشگرهای ۱۴۴ هرتزی هم در این رزولوشن نمیتوانند قدرتِ این کارتِ گرافیکی را به چالش بکشند، تصمیم گرفتیم که بنچمارک گیری در دقتِ 1080p را با این مدل کارتِ گرافیکی به علتِ کاربردی نبودن کنار بگذاریم. تنها کاربردِ اختصاصی این رده کارت گرافیکی در رزولوشنِ معمولی 1080p، هنگامِ فعال کردنِ قابلیت Ray Tracing خواهد بود که آن را هم در بنچمارکِ مربوطه لحاظ کردهایم. حتی برخی بازیها در این رزولوشن با این کارت CPU-Bound یا محدود به راندمانِ پردازنده خواهند شد.
همانگونه که در آزمونِ 1440p مشاهده میکنید، RTX 2080 Ti از گیگابایت توانسته پرچمدارِ نسلِ قبلی، GTX 1080 Ti را با تفاوتِ میانگینِ ۲۲ فریم در ثانیه پشتِ سر بگذارد که نشاندهندهی پیشتازی ۲۰ درصدیِ این مدل کارتِ گرافیکی است. این کارت همچنین به میزانِ ۴۸ درصد سریعتر از کارتِ دیگرِ محصولِ گیگابایت یعنی GTX 1080 G1 Gaming عمل کرده است.
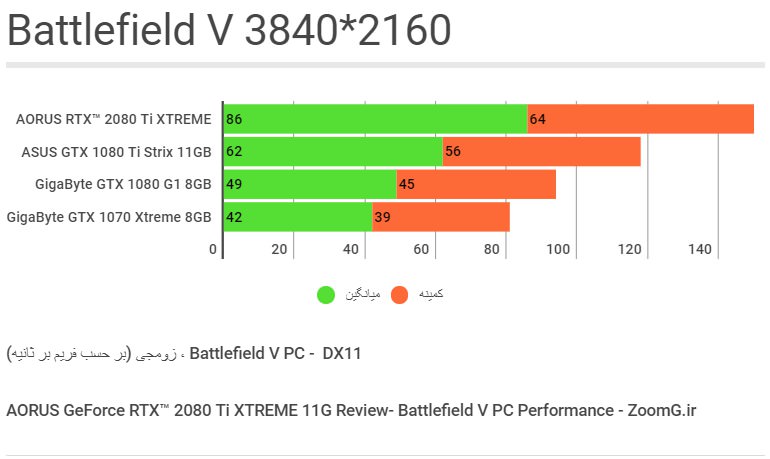
آزمونِ 4K با بتلفیلد نشان داد که قویترین مدلِ اختصاصی نسلِ جدید در دقتِ 4K حدودِ ۳۸ درصد راندمانِ بیشتری را نسبت به قویترین مدلِ نسلِ پاسکال ارائه میکند. افزایشِ اتکا به پهنای باندِ حافظه در این رزولوشن و گلوگاه شدنِ ۱۰۰ درصدیِ GPU، دلیلِ افزایشِ تفاوتِ راندمانِ بهدست آمده در این رزولوشن نسبت به آزمونِ قبلی است.
خبر خوب اینکه Battlefield V با RTX 2080 Ti رکوردی نزدیک به ۹۰ فریم در ثانیه را در نرخِ متوسط ثبت کرده و حتی در کمینهی فریم هم هیچگاه بازی به نرخِ پایینتر از مرزِ ۶۰ فریم بر ثانیه سقوط نخواهد کرد، درحالیکه GTX 1080 Ti در شرایطِ مشابه برای حفظِ نرخِ فریم در محدودهی ۶۰ فریم در ثانیه در حالِ تقلا به سر میبرد.
Just Cause 4
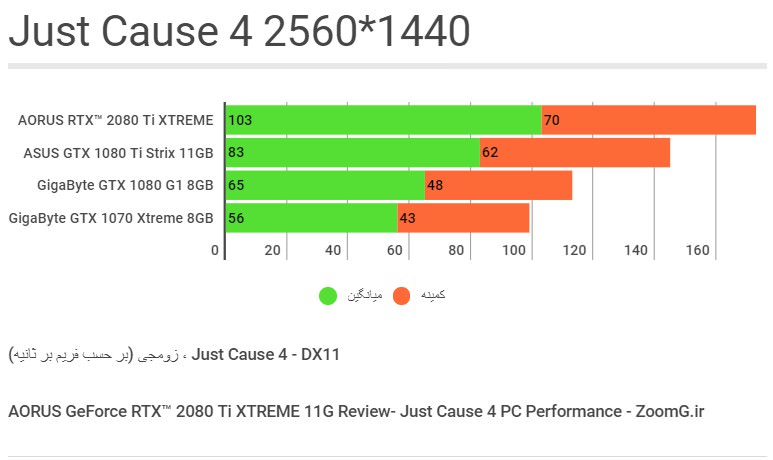
شاید آخرین نسخهی بازی جاست کاز از نظرِ گرافیکِ فنی همسطحِ بتلفیلد نباشد، اما موتور گرافیکی آن و امکاناتی که در اختیار میگذارد را میتوان نمونهی خوبی برای سنجشِ راندمانِ این کارت گرافیکی در مقایسه با مدلهای دیگر در نظر گرفت. در اینجا Aorus RTX 2080 Ti گیگابایت توانسته پرچمدارِ سابق را با اختلافِ ۲۴ درصد پشت سر بگذارد که نتیجهای مطابقِ انتظار است.
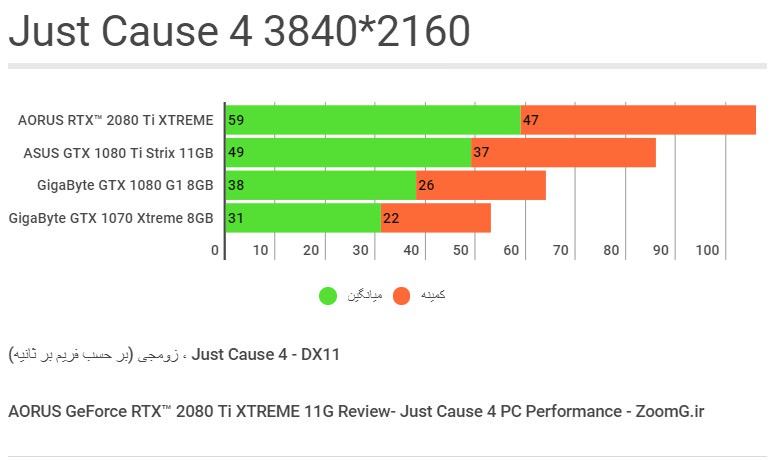
Just Cause 4 اولین عنوانی است که در این بررسی میبینیم با کارتِ گرافیکِ پرچمدارِ جدید، تواناییِ اجرا در رزولوشنِ 4K با میانگینِ حدود ۶۰ فریم را پیدا میکند، کاری که به علتِ سنگینیِ پردازش در این سطح از عهدهی GTX 1080 Ti خارج است.
Far Cry 5
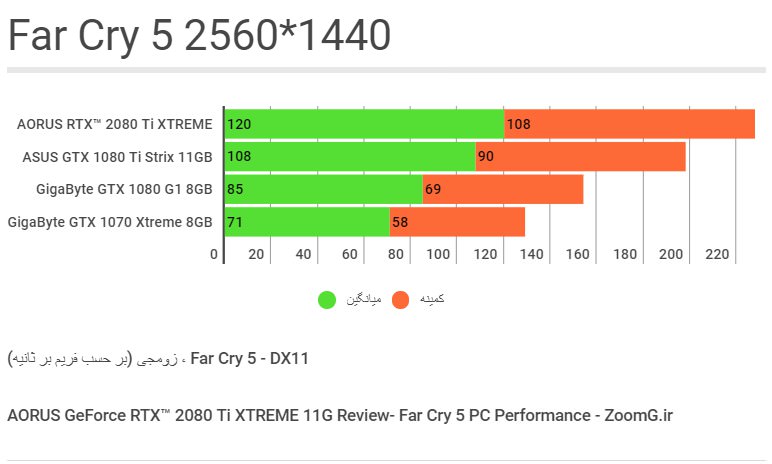
در آزمایشهای گذشته دیدهایم که راندمانِ Far Cry 5 به سرعتِ پردازنده هم وابستگی دارد. بااینحال در بنچمارکِ این بازی با بالاترین تنظیماتِ گرافیکی توانستهایم در دقتِ 2K میانگینِ ۱۲۰ فریم در ثانیه را دربرابرِ تنها ۱۰۸ فریم در ثانیه از GTX 1080 Ti ثبت کنیم که اختلافی ۱۱ درصدی است.
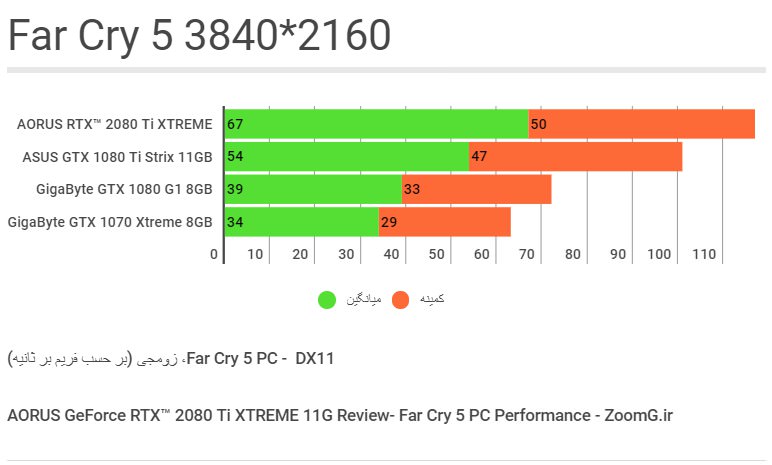
اما در دقتِ 4K کمترین حدِ وابستگی به CPU را داریم و بازیها بیشتر GPU-Bound هستند. در اینجا ۲۴ درصد بهبود از ارتقای 1080Ti به RTX 2080 Ti را شاهد هستیم.
Assassin's Creed: Odyssey
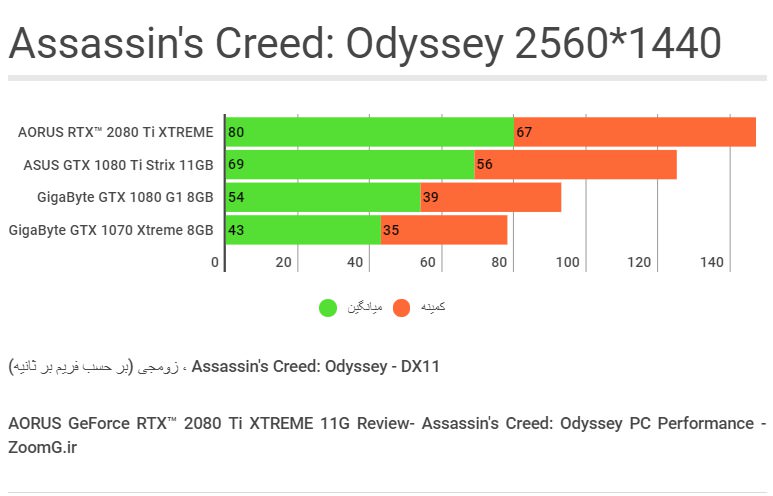
بررسیهای قبلی ما نشان داده بود که AC: Odyssey در بینِ بازیهای اخیر بیشترین بار پردازشی را روی CPU قرار میدهد و چون کاملا بهینه نیست، قویترین پردازندهها هم هنوز میتوانند ترمزِ آن را بگیرند. در اینجا AORUS RTX 2080 Ti XTREME توانسته به نرخِ میانگینِ ۸۰ فریم در ثانیه برسد که پیشرفتی ۱۵ درصدی است.
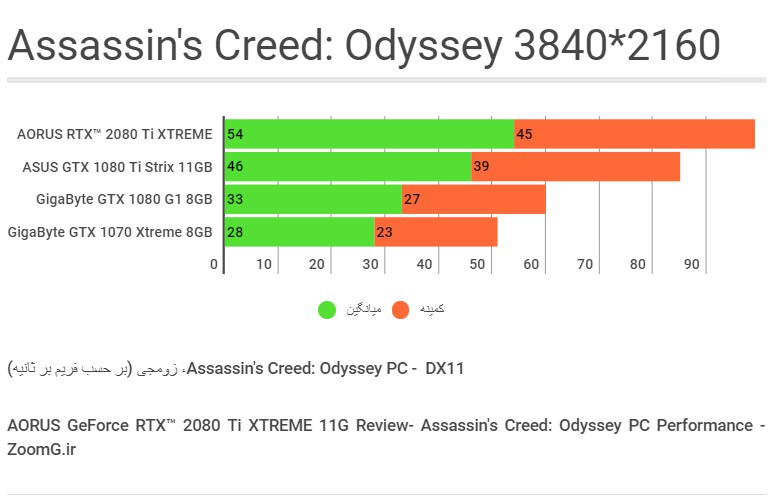
2080Ti برای اولینبار توانسته است در بالاترین تنظیمات در 4K از مرزِ ۵۰ فریم در ثانیه عبور کند که نتیجهای نسبتا ایدهآل در این بازی محسوب میشود. اما الگویی که در این آزمونها جلبِ توجه میکند این است که در بررسیهای قبلی زومجی، افزایش راندمانی که با ارتقا از GTX 980 Ti به GTX 1080 TI دیده بودیم، بیشتر از میزانِ افزایشِ راندمانی است که اکنون با مقایسهی نسلِ پاسکال نسبت به تورینگ شاهد هستیم.
راندمان Ray Tracing
BattleField V - RTX
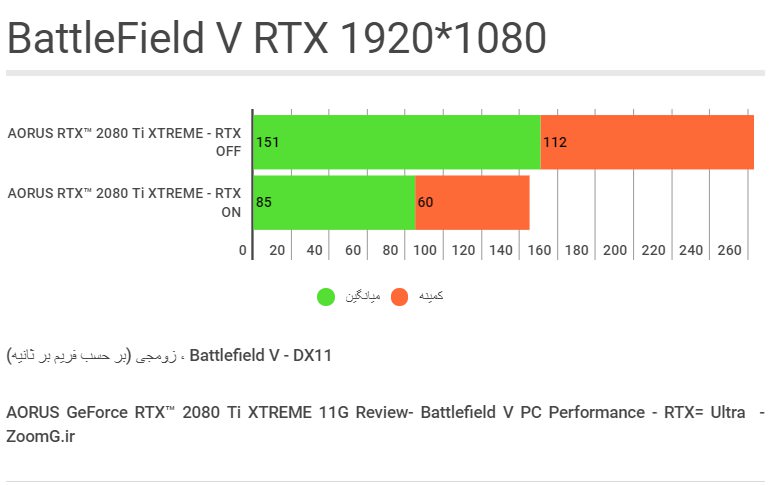
از آنجایی که مشخص شده فعال شدنِ RTX تاثیرِ زیادی روی راندمان دارد، رزولوشنِ 1080p را هم به بررسی اضافه کردیم. در اینجا ۵۶ درصد کاهشِ راندمان را با فعالسازی RTX شاهد هستیم که حدودِ نیمی از نرخِ فریم را به خاطرِ پیادهسازیِ با کیفیتترِ انعکاسها به کمکِ تکنیکِ رهگیری پرتو کاسته است. در عینِ حال بازی همچنان کاملا روان اجرا میشود و افتِ فریمی قابلِ تشخیص نیست.
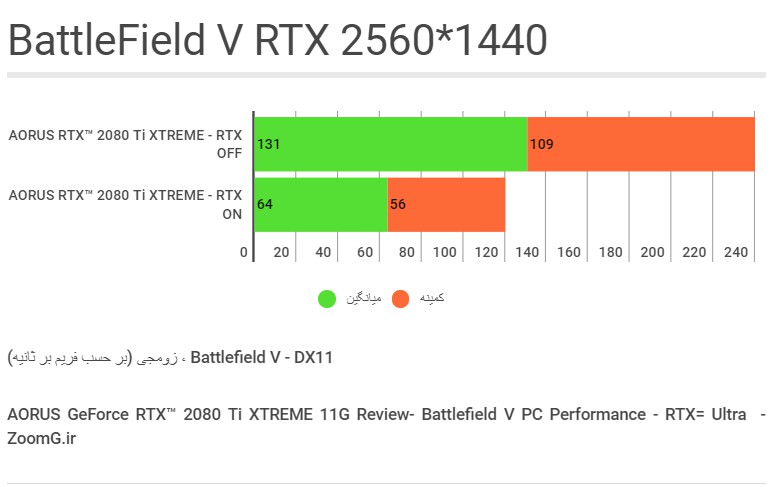
در اینجا هم به مقدارِ ۴۸ درصد از راندمان کاسته شده، اما به مددِ بروز رسانیِ موثرِ دایس برای بتلفیلد و بهبود راندمان برای RTX، هنوز در رزولوشنِ 2K هم میتوانیم تضمینِ دستیابی به کمینهی ۶۰ فریم در ثانیه را با کارتِ قدرتمندِ Aorus GeForce RTX 2080Ti Xtreme در اختیار داشته باشیم.
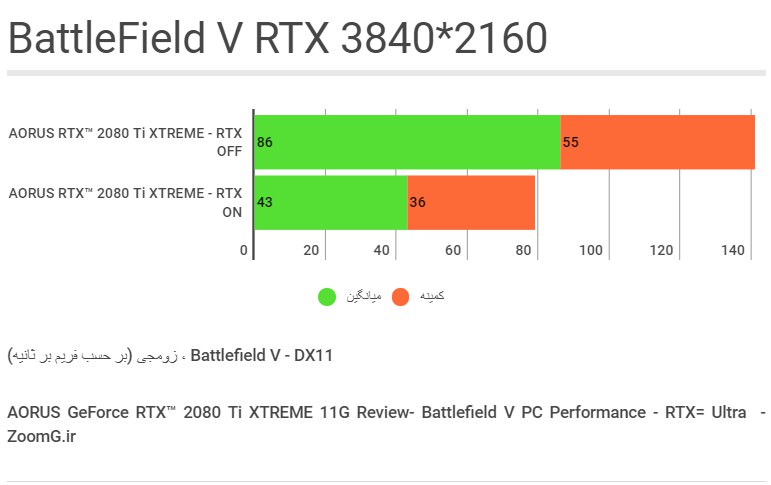
اما در دقتِ 4K به نظر میرسد که یا باید به محدودهی ۳۰ تا ۴۰ فریم در ثانیه بسنده کنیم، یا اینکه فعلا قیدِ استفاده از RTX را در این دقتِ فوقالعاده بالا بزنیم. تنظیماتِ پایینتر برای Ray Tracing هم قابلِ انتخاب هستند، اما از کیفیتِ بصریِ اجرای تکنیک هم میکاهند.
اورکلاک
هر یک از سازندهها معمولا نرمافزار اورکلاکینگِ مخصوصی را برای اورکلاکِ کارتهای گرافیکی معرفی میکنند. گیگابایت هم AORUS ENGINE را برای این کار در نظر گرفته که توسطِ آن میتوان فرکانسهای GPU و Memory و همینطور سقفِ TDP و ولتاژِ GPU را برای کارتهای پشتیبانی شده افزایش داد.
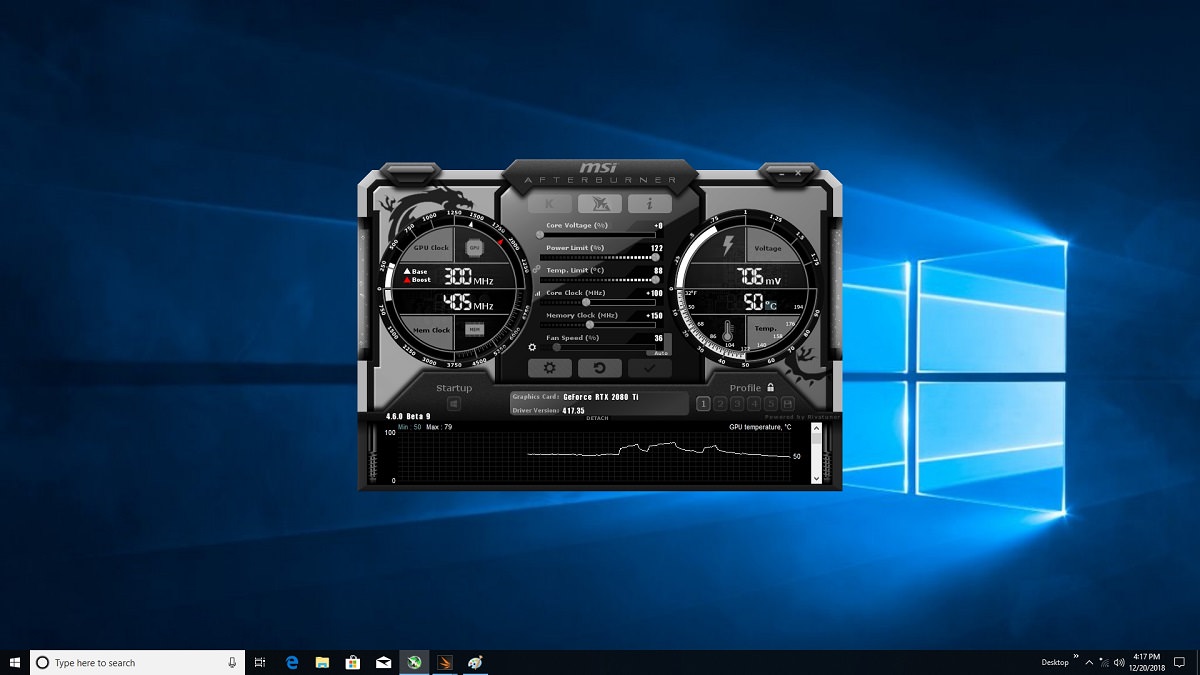
مثلِ همیشه از MSI AfterBurner برای اورکلاکِ کارت استفاده کردیم و توانستیم فرکانسِ GPU را تا ۱۰۰ مگاهرتز افزایش دهیم. در فرکانسهای بالاتر مثلِ ۱۳۰ مگاهرتز، کارت گرافیک گرافیک ناپایدار بود و تستِ پایداری ناتمام میماند. همچنین تستِ 3DMark Fire Strike Extreme Stress Test را در ۲۰ تکرارِ متوالی برای سنجشِ پایداریِ کارت در فرکانسِ اورکلاک شده استفاده کردیم.
بنچمارک OC
3MARK 2013 DX11 OC
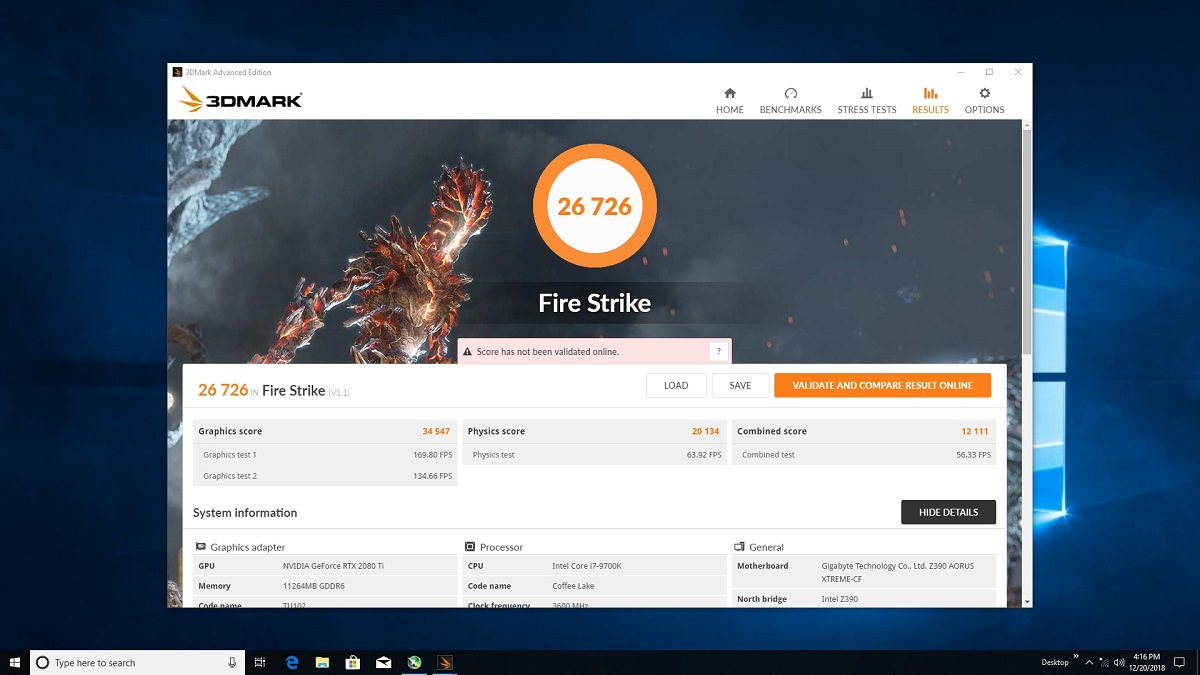
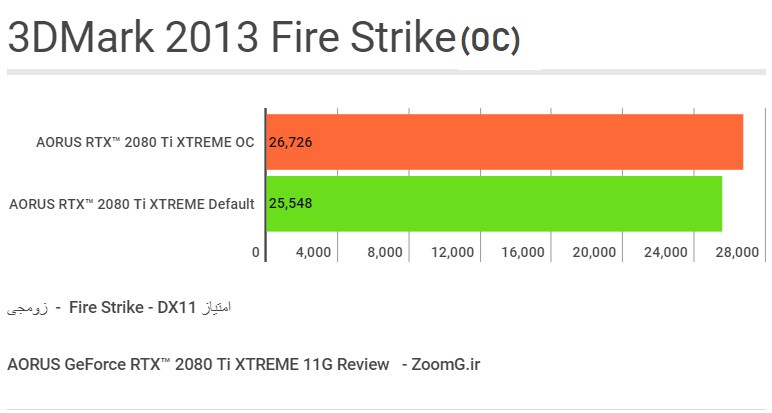
در تستِ دایرکت ایکس 11 با اورکلاکِ دستیِ ما، حدود ۴ درصد به راندمانِ 3DMark Graphic Test با فرکانسِ پیش فرض افزوده شد.
3DMARK 2013 DX12 OC
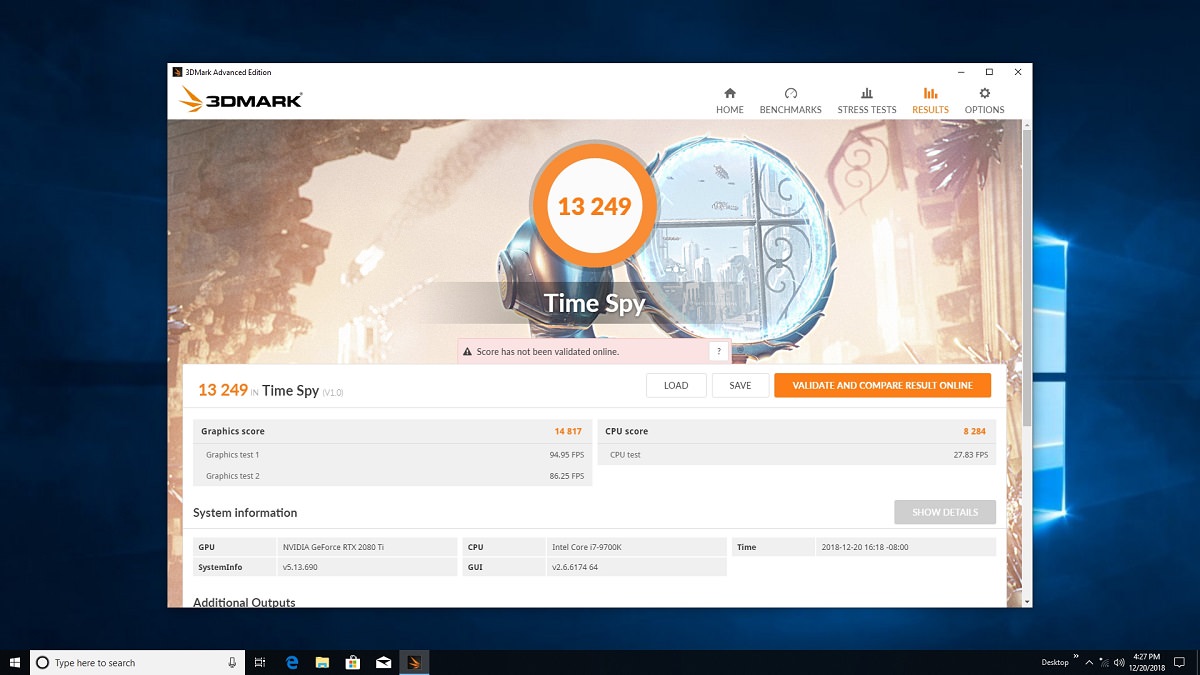
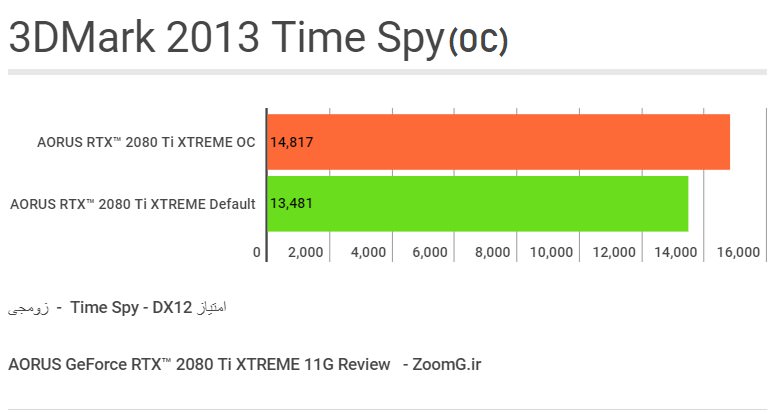
اما در تستِ دایرکت ایکس 12 با اورکلاک، به میزانِ ۹ درصد به راندمانِ 3DMark Graphic Test با فرکانسِ پیش فرض اضافه شد که نشان میدهد اورکلاکِ ما در راندمانِ بازیهای مبتنی بر دایرکت ایکس 12، احتمالا بهبودِ ملموستری را ایجاد خواهد کرد.
دما



در حالتِ فرکانس پیش فرض بالاترین دمای کارت ۸۰ درجه و در حالتِ اورکلاک هم به ۸۴ درجهی سانتیگراد رسید که دمای قابل قبول (نه عالی) برای این تراشهی قدرتمندِ گرافیکی محسوب میشود و نشان میدهد که خنککننده به خوبی میتواند دمای کارت را در سناریوهای سخت نیز کنترل کند. بیشترین دما را در BattleField V در هنگامِ فعال بودنِ Ray Tracing یا همان DXR در بازی تجربه کردیم.

جمع بندی
بررسی کارت گرافیکِ AORUS GeForce RTX 2080 Ti XTREME اولین بررسی ما از محصولی در این رده بود که به ما امکان داد علاوهبر آزمودنِ تواناییِ تراشهی پیشرفتهی تورینگ در اجرای بازیها، به قابلیتهای جدیدِ آن در ارائهی تکنیکِ رهگیری پرتو در زمانِ واقع یا به اختصار RT و همینطور تکنیکِ DLSS نگاهی داشته باشیم. البته بررسی ما از راندمانِ RTX فقط به بازی Battlefield V محدود شد که از این تکنیک فقط در شبیهسازیِ بازتابها و انعکاس استفاده کرده بود و بازیهای دیگر مثل Metro Exodus و Shadow of the Tomb Raider از آن برای نورپردازیِ طبیعی و ایجادِ سایههای واقعیِ اشیا بهره گرفتند و هر یک در هنگام اجرای آن، افتِ راندمانِ متفاوتی را تجربه میکنند.
موضوعِ مهم دیگری که برای کاربران مطرح است، ارزش داشتنِ این قابلیتهای جدید نسبت به قیمتِ بالای این کارتهای گرافیکی است. پاسخِ روشن به این پرسش زمانی مهیا میشود که مدتِ زیادی از عرضهی این محصول بگذرد و بازیهای جدید با این قابلیت هم به بازار عرضه شده باشند و درواقع جهت گیریِ بازیسازان در استقبال و بکارگیریِ این امکاناتِ جدید مشخص شده باشد. هنوز برخی بازیها هستند که قرار است در آینده با یک یا هر دو قابلیتِ Ray Tracing و DLSS عرضه شوند که طبعا هدفشان درنهایت بهبودِ جلوههای بصری است و باید دید که تا چه حد در این زمینه به موفقیت خواهند رسید. هر چند که به عقیدهی برخی، راندمانِ واحدهای RT و DLSS در معماریِ تورینگ هنوز پایین است و به بلوغِ مناسب نرسیدهاند و بنابراین تاثیرگذاریِ آنها در بازیهای جدید هم به علتِ افتِ قابلِ توجهِ راندمان، هرگونه قضاوت در موردِ سودمند بودن یا نبودنِ استفاده از آنها را با ابهام مواجه میکند.
اما صرفا از جنبهی راندمانِ خالص در بازیها بدون درنظرگرفتنِ تکنیکهای جدید، پیشرفتِ نسلِ تورینگ نسبت به پاسکال کمتر از نسلِ گذشته به نظر میرسد که قاعدتا نمیتواند خریدِ محصولاتِ جدید را بهتنهایی ضروری یا توجیه کند، مگر اینکه انویدیا قیمتِ کارت گرافیکهای خود را به شکلِ محسوسی در بازار بکاهد. در سالهای گذشته در بررسی GTX 1080 در برخی عناوین تا ۷۵ درصد بهبودِ راندمان را نسبت به GTX 980 ثبت کرده بودیم که میتوانست ارتقا به نسلِ جدید را برای بسیاری از کاربرانی که خواهانِ تجربهی روانتری در بازیها بودند توجیه کند، ضمن اینکه قیمت پرچمدارهای نسلِ پاسکال بین ۱۰۰ تا ۲۰۰ دلار پایینتر تعیین شده بود.
فارغ از قابلیتهای تکنیکیِ و راندمان، کارت گرافیک GeForce RTX 2080 Ti XTREME از طراحیِ ظاهری منحصر به فردی در میانِ مدلهای پرچمدار از سازندگانِ دیگر برخوردار شده که آن را از این جنبه سرآمد کرده است. نورپردازی RGB تعبیه شده روی فنهای سهگانهی این کارت، جلوههای بسیار زیبایی ایجاد میکنند که در محصولاتِ مشابه که بهتازگی بیشترشان با قابلیت RGB به فروش میرسند قابلِ تولید نیست. نمایی از نورپردازیِ این محصول را در ویدیوی زیر میبینید:
از نظر خنک کنندگی و دما هم مدلِ اکستریم ثابت کرد که در شرایطِ پردازشِ سنگین هم از تواناییهایش کاسته نمیشود و در کنترلِ شرایطِ کاری بینقص است. افزایشِ دور فنها در پردازشهای نزدیک به ۱۰۰ درصدیِ طولانی مدت اجتناب ناپذیر است و در این حالت صدای فنها اگر کارت داخلِ کیس نصب باشد هم قابلِ تشخیص است، اما از نظرِ ما آزاردهنده نیست. هر چند که ترجیح میدادیم بهرهوریِ خنککننده در هنگامِ لود بهتر از این باشد و دمای پایینتری را شاهد باشیم. برای این تراشههای بزرگ و قدرتمند مانند TU102، مهمترین عامل کنترلِ دما و توان تا جایی است که کمترین افتِ فرکانسِ کاری و ولتاژ را در هنگامِ کار شاهد باشیم و درواقع عملکردِ محصول در بازهی مشخصی پایدار و با ثبات باشد، در غیر این صورت افتِ راندمان نتیجهی مستقیمِ افزایشِ دما و ناتوانیِ خنککننده در کنترلِ عواملِ مذکور خواهد بود که قطعا مطلوبِ نظر کاربران هم نیست.

در پایان AORUS GeForce RTX 2080 Ti XTREME را محصولی یافتیم که بهعنوان یکی از سریعترین شتابدهندههای گرافیکیِ حالِ حاضر در دنیا، بهراحتی امکانِ برخورداری از بالاترین فریمهای ممکن را در سنگینترین بازیها به گیمرهای خورهی بازیهای پیسی میدهد و مخصوصِ آنهایی است که بالاترین راندمان را با نمایشگرهای 2K و البته با اطمینانِ بیش از گذشته در نمایشگرهای 4K انتظار دارند. اگر هم به تجربهی جلوههای طبیعیِ حاصل از کارکردِ واحدِ RT یا افزایشِ راندمانِ ناشی از فناوریِ DLSS علاقه داشته باشید هم طبعا هیچ انتخابی بالاتر از یک مدلِ تا به دندان مسلح از RTX 2080 Ti نخواهید یافت. در بسیاری از بازیها دسترسی به نرخهای بالای ۱۰۰ فریم در ثانیه با این کارتِ گرافیک مقدور میشود و دسترسی به محدودهی ایدهآل ۶۰ فریم در ثانیه در دقتِ 4K هم توقعی حداقلی و عادی با این کارت محسوب خواهد شد. اینکه دیدِ ما نسبت به استفاده از Ray tracing و تکنیکهای هوش مصنوعی در DLSS همچنان امیدوار کننده و مثبت باشد نیز به رواجِ آنها در بازیهای آینده و در دسترس بودنِ آنها منوط خواهد بود.
مشخصات فنی کامل، بهترین قیمت کارت گرافیک در فروشگاههای اینترنتی و مقایسهی کامل انواع کارت گرافیک را در بخش محصولات مشاهده کنید؛ انواع کارت گرافیک انویدیا Geforce و Quadro و کارت گرافیک AMD رادئون برای مقایسه و خرید در دسترس کاربران است.
کارت گرافیک AORUS GeForce RTX 2080 Ti XTREME گیگابایت توسط نمایندگی در اختیار زومجی قرار گرفته است.
تهیه شده در بخش سختافزار زومجی